Software delivery has never been more critical to the success of business in every industry. It’s also never been more complex. Expectations for delivering high-quality software incredibly fast have skyrocketed - yesterday’s most exceptional product experiences are expected today to be more beautiful, intuitive, powerful, and affordable.
But the landscape of tools, platforms, and architectures is constantly evolving. With this rapid pace of change and the growing challenges of complexity, how can engineering teams not only succeed but beat out the competition?
Jeremy Meiss
DevRel & Community professional
Open to work
So back to the tech industry…
We have entered into a period of immense change, and with the global economic uncertainties presented impacting companies of all sizes.
Amidst this environment, stability and reliability have become increasingly important to businesses globally. The ability to provide a reliable, stable platform to customers has become a crucial value metric to engineering teams and will only continue to increase in importance this year.
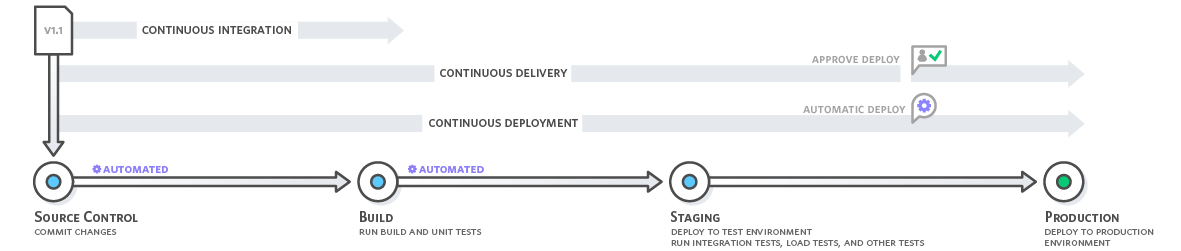
Continuous Delivery
Source: AWS Continuous Delivery
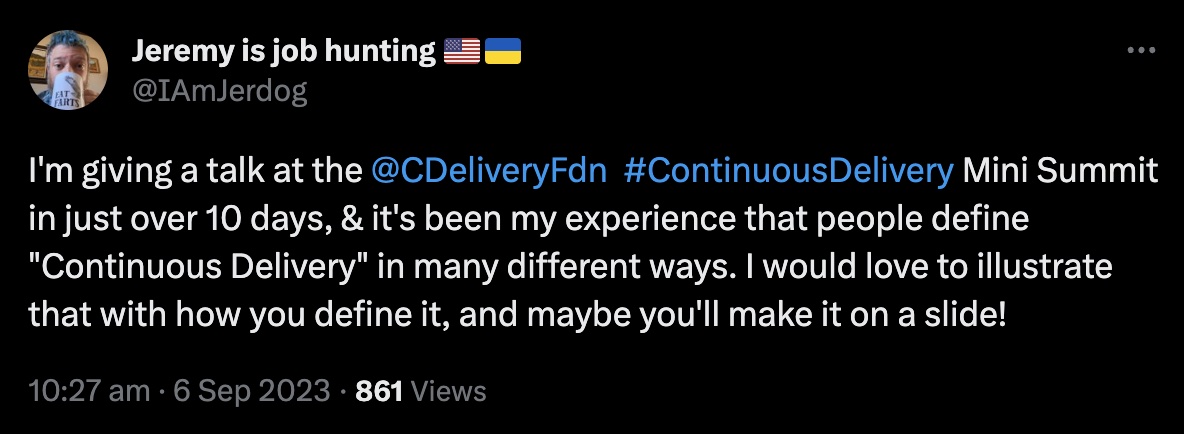
What would you say CD is?
I put out a question a few weeks ago about how people would define CD… Anyone want to take a stab at it?
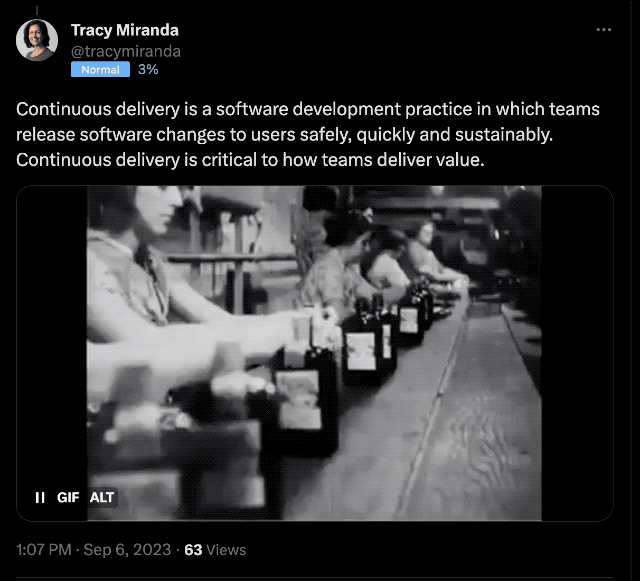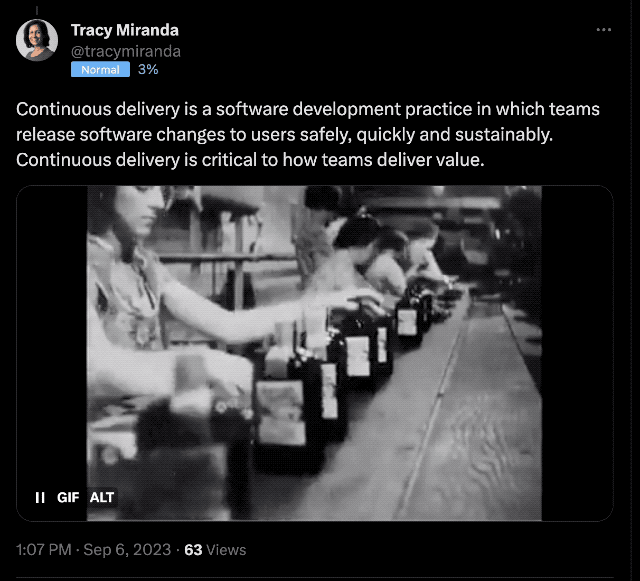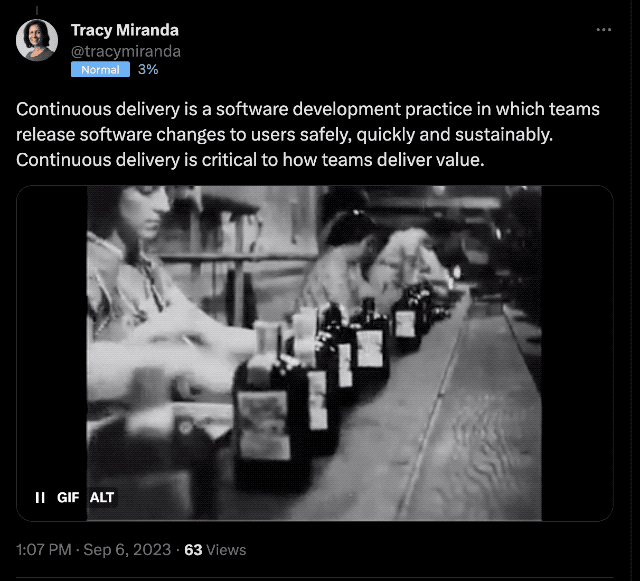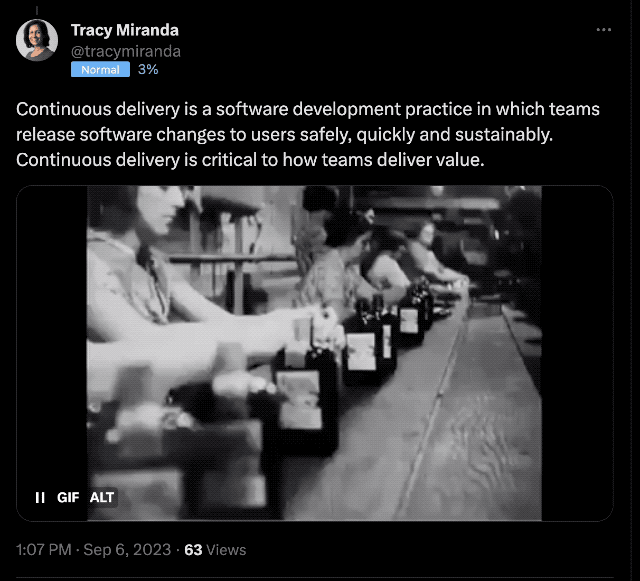
…I only got one response - Tracy Miranda, who provided a really good definition
Continuous Delivery
the ability to get changes-—features, configuration changes, bug fixes, experiments—-into production or into the hands of users, safely and quickly in a sustainable way.
– Jez Humble. DevOpsDays Seattle 2017. Continuous Delivery Sounds Great But It Won’t Work Here
Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way.
Modern Software Delivery
engineers owning their own code in production
practicing observability-driven development
testing in production separate deploys from releases with feature flags
continuous deployment/delivery
– Charity Majors, Fintech DevCon 2023, Twitter thread
In a recent talk at FinTech DevCon, Charity Majors, co-founder/CTO @Honeycomb, talked about a list of modern development practices. With the continuous delivery point, she focused heavily on…
Deploy as fast as possible, as automated as possible
– Charity Majors, Fintech DevCon 2023
…the importance of deploying as fast as possible, as automated as possible.
Over the last few years we’ve seen a jump in companies starting to understand this importance Charity speaks about, but too often they’s done it with a “grow at all costs” mentality. But we all know that software systems are complex, and getting more so, and the cognitive load necessary to maintain those systems is really overwhelming for both Dev and Ops roles. All that led to cut corners, and it feels like we’ve seen more and more core systems experience outages as a result.
Some of you may be familiar with the industry reports like the State of DevOps Report, the State of Cloud Native Report, and the CDF’s own State of Continuous Delivery Report. These reports are great for understanding the industry as a whole, but they don’t really give you a good idea of how your team is performing as they’re largely based on self-reported data, and the memory of those taking the surveys. The report I will be talking about today is the State of Software Delivery Report, which CirclecI started compiling yearly in 2019, and is largely based on anonymized data from CircleCI’s own platform of how developers and teams are actually working.
Image: Consumer Choice Center
I don’t believe in one-size-fits-all success metrics, because you’re company and business isn’t the same as the person sitting next to you. Unless you’re coworkers, which could make this a really uncomfortable, and revealing, conversation.
CI/CD Benchmarks for high-performing teams
Duration
Mean time to resolve
Success rate
Throughput
So we’re going to be talking about these standard engineering metrics, and how the data reveals some recommended benchmarks for each. But I do want to stress that these are “recommended”, and that ultimately your business needs will play a big part into what a high-performing engineering team looks like for you.
We’ll also talk a little bit about the optimization steps necessary - sometimes through culture, structure, and strategy - in order to make sure you’re maintaining a key ingredient in achieving success: developer happiness.
Duration
the foundation of software engineering velocity, measures the average time in minutes required to move a unit of work through your pipeline
Duration is the foundation of software engineering velocity. Now this unit of work does not always mean deploying to production – it may be as simple as running a few unit tests on a development branch.
Duration, then, is best viewed as a proxy for how efficiently your pipelines deliver feedback on the health and quality of your code. The core promise of most software delivery paradigms, from Agile to DevOps, is speed: the ability to take in information from customers or stakeholders and respond quickly and effectively.
These rapid feedback and delivery cycles don’t just benefit an organization’s end users; they are crucial to keeping developers happy, engaged, and in an uninterrupted state of flow.
Yet an exclusive focus on speed often comes at the expense of stability. A pipeline optimized to deliver unverified changes is nothing more than a highly efficient way of shipping bugs to users and exposing your organization to unnecessary risk. To be able to move quickly with confidence, you need your pipeline to guard against all potential points of failure and to deliver actionable information that allows you to remediate flaws immediately, before reaching prod. So what is the ideal duration?
Duration Benchmark
<=10 minute builds
"a good rule of thumb is to keep your builds to no more than ten minutes. Many developers who use CI follow the practice of not moving on to the next task until their most recent check-in integrates successfully. Therefore, builds taking longer than ten minutes can interrupt their flow."
– Paul M. Duvall (2007). Continuous Integration: Improving Software Quality and Reducing Risk
To get the maximum benefit from your workflows, the recommendation is to aim for a duration of 10 minutes, which is a widely accepted benchmark that dates back to Paul M. Duvall’s influential book on Continuous Integration. At this range, it is possible to generate enough information to feel confident in your code without introducing unnecessary friction in the software delivery process.
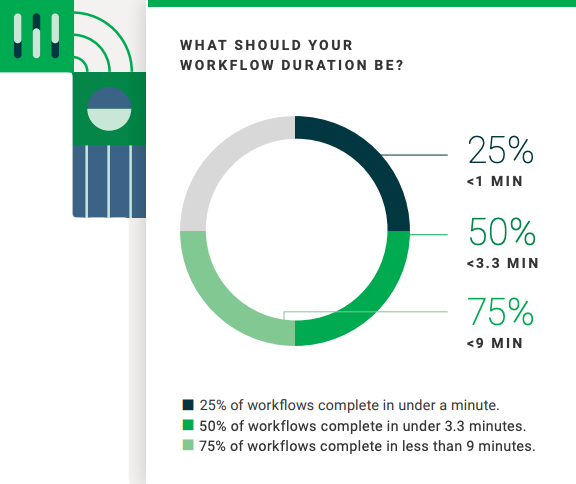
Duration: What the data shows
Benchmark: 5-10mins
Among the workflows observed in the dataset, 50% completed in 3.3 minutes or less; 25% of workflows completed in under a minute; 75% completing in under 9. The 95th percentile at approx 11min reflects a lot of longer-running workflows taking 27 minutes or more to complete.
Improving test coverage
Add unit, integration, UI, end-to-end testing across all app layers
Add code coverage into pipelines to identify inadequate testing
Include static and dynamic security scans to catch vulnerabilities
Incorporate TDD practices by writing tests during design phase
Many teams continue to bias toward speed rather than robust testing. But the number one opportunity for improving performance across all four software delivery metrics is to enhance your test suites with more robust test coverage.
Optimizing your pipelines
Use test splitting & parallelism for simultaneous multiple tests
Cache dependencies & data to avoid rebuilding unchanged code
Use Docker images custom made for CI environments
Choose the right machine size for your needs
To balance workflow speed and test coverage, prioritization has to take center stage, which means asking: “Which features are part of the critical path? Where can you afford more experimentation and risk?” These techniques, along with buy-in from important stakeholders on the right balance between test coverage and workflow speed, will help you optimize your pipelines.
Teams who focus only on speed, not only will spend more time rolling back all their broken updates and debugging in production, BUT they’ll also face greater risk to to their org’s reputation and stability. Optimizing workflow durations means combining comprehensive test practices with efficient workflow orchestration.
Mean time to Recovery
the average time required to go from a failed build signal to a successful pipeline run
MTTR is a metric indicative of your team’s resilience and ability to respond quickly and effectively to feedback from your CI system. Meaning, it’s the best indicator of your org’s DevOps maturity.
The way user’s, and most org’s, see it, nothing is more important than your team’s ability to recover from a broken build. Customers are unlikely to notice the steady stream of granular updates made throughout the week, but they damn well will notice when broken code slips through your test suite.
"A key part of doing a continuous build is that if the mainline build fails, it needs to be fixed right away. The whole point of working with CI is that you're always developing on a known stable base."
– Martin Fowler (2006). “Continuous Integration.” Web blog post. MartinFowler.com
In 2006, Martin Fowler described the north star for software teams’ MTTR: “Fix broken builds immediately.” Does this mean your team should aim for resolving failed workflows within a matter of seconds? Or better yet avoid build failures at all costs? Not at all! Broken builds happen, but with proper tests in place, the info from a red build has as much (if not more) value for development teams as a passing green build.
MTTR Benchmark
<=60min MTTR on default branches
As a result, it’s recommended that you aim to fix broken builds on any branch in under 60 minutes. Depending on the scale of your user base and criticality of your application, your target may be significantly lower or higher. However, the ability to recover in under an hour is strongly correlated with the other metrics, and will allow your organization to avoid the worst outcomes of prolonged failures.
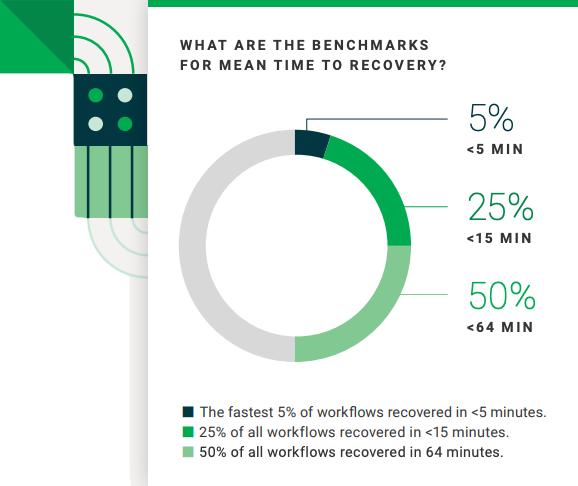
MTTR: What the data shows
Benchmark: 60 mins
The data set shows 50% recovery in 64min or less, down from almost 10min longer. The top 25% recovered in 15 min or less, and the top 5% in under 5.
Treat your default branch as the lifeblood of your project
The first step to lowering recovery times is to treat your default branch as the lifeblood of your project – and by extension, your organization. While red builds are inevitable, getting your code back to green immediately should be everyone’s top priority. With a vigilant culture in place, your organization will be poised to leverage information from your CI pipeline and remediate failures as soon as they arise.
Getting to faster recovery times
Treat default branch as the lifeblood of your project
Set up instant alerts for failed builds (Slack, Pagerduty, etc.)
Write clear, informative error messages for your tests
SSH into the failed build machine to debug remote test env
Recovery speed is completely bound with pipeline duration: shortest possible TTR is the length of your next pipeline run. So all of these techniques require the other optimizations before you can get to faster recovery times.
Success rate
number of passing runs divided by the total number of runs over a period of time
Along with MTTR, success rate is another indicator of the stability of your AppDev process. But, the impact of success rate on customers and developers varies according to a few factors: What branch was the failure on (default or dev)? Did the workflow involve a deployment? How important is the app or service?
Failed signals are not all bad
A failed signal isn’t necessarily indicative of something going wrong or, a problem that needs to be addressed on a deeper level than your standard recovery processes. Far more important is your team’s ability to take in the signal quickly (DURATION) and remediate the error effectively (MTTR). Failed workflows that delivers fast, valuable signals are far more desirable than a passing workflow with little to no reliable info.
Success rate benchmark
90%+ success rate on default branches
Maintaining a success rate of 90% or higher on default branches is a reasonable target for the mainline code of a mission-critical app, where changes should be merged only after passing a series of well-written tests. Topic branch failures are generally less disruptive than those occuring on the default branch. It’s important for your team to set its own benchmark for success on non-default branches depending on how you use them.
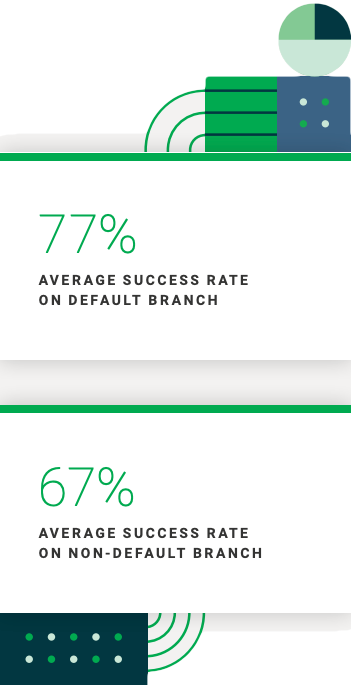
Success rate: What the data shows
Benchmark: 90%+ on default
Back to the data: Success rates on the default branch were 77% on average, with 67% on non-default branches. The trends show that success rates on default branches have held steady over the past several reports. While neither reaches the benchmark of 90%, the pattern of non-default branches having higher numbers of failures indicates teams are utilizing effective branching patterns to isolate experimental or risky changes from critical mainline code. And while success rates haven’t moved much over the previous reports, recovery times have fallen sharply. This is a good sign that orgs are prioritizing iteration and resilience over momentum-killing perfectionism.
Throughput
average number of workflow runs that an organization completes on a given project per day
Throughput traditionally reflects the number of changes your developers are committing to your codebase in a 24-hour period
It is also useful as a measurement of team flow as it tracks how many units of work move through the CI system. When performed at or above recommended levels, throughput puts the “continuous” in continuous delivery — the higher your throughput, the more frequently you are performing work on your application.
Of course, throughput also tells you nothing about the quality of work you are performing, so it is important to consider the richness of your test data as well as your performance on other metrics such as success rate and duration to get a complete picture. As with duration, a high throughput score means little if you are frequently pushing poor quality code to users. So what’s ideal?
Throughput benchmark
It depends.
Of all the metrics, throughput is the most subjective to org goals. A large cloud-native org actively developing a critical product line will require far higher levels of throughput than a small team maintaining legacy software or niche internal tooling. It really does depend. There’s not a universally applicable throughput target - it needs to be set according to your internal business requirements. The type of work, the resources available, the expectations of your users all play into it. Far more important than the volume of work you’re doing is the quality and impact of that work.
Throughput: What the data shows
Benchmark: at the speed of your business
So, in the data the median workflow ran 1.54 times per day, with the top 5% ran 7 times per day or more - not much change from previous reports. Overall, the average project had 2.93 pipeline runs in 2023, a slight uptick compared to 2.83 in 2022. This uptick isn’t much, but when combined with the sharp decrease in MTTR, it could reflect that teams are committing to smaller, more frequent changes to limit the complexity of outages and achieve faster, more consistent feedback on the state of their applications.
Throughput is the most dependent on the other metrics
Throughput is the most dependent on the other metrics. How long your workflows take to complete, how often they fail, and the amount of time it takes to recover from a failure all affect your developers’ ability to focus on new work and the frequency of their commits. To improve your team’s throughput, you have to first address all the potential underlying factors that can affect team productivity, as previously identified.
Throughput is often a trailing indicator of other changes in your processes and environment. Rather than setting an arbitrary throughput goal, set a goal that reflects your business needs, capture a baseline measurement, and monitor for fluctuations that indicate changes in your team’s ability to do work. Achieving the right level of throughput means staying ahead of customer needs and competitive threats while also continuously validating the health of your application and development process.
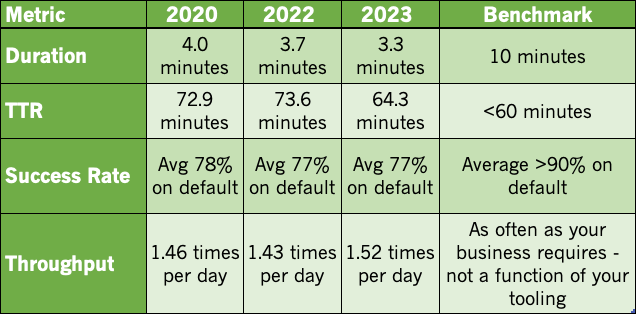
To sum up the data, here are the metrics over the last few years of the SoSDR. When you measure, and then optimize, these metrics, your teams (and company) gain a tremendous advantage over organizations that do not track these key metrics.
2023 State of Software Delivery Report
go.jmeiss.me/SoSDR2023
Thank You.
/in/jeremymeiss
@IAmJerdog
@jerdog
@jerdog@hachyderm.io
























 /in/jeremymeiss
/in/jeremymeiss @IAmJerdog
@IAmJerdog @jerdog
@jerdog @jerdog@hachyderm.io
@jerdog@hachyderm.io